Introduction
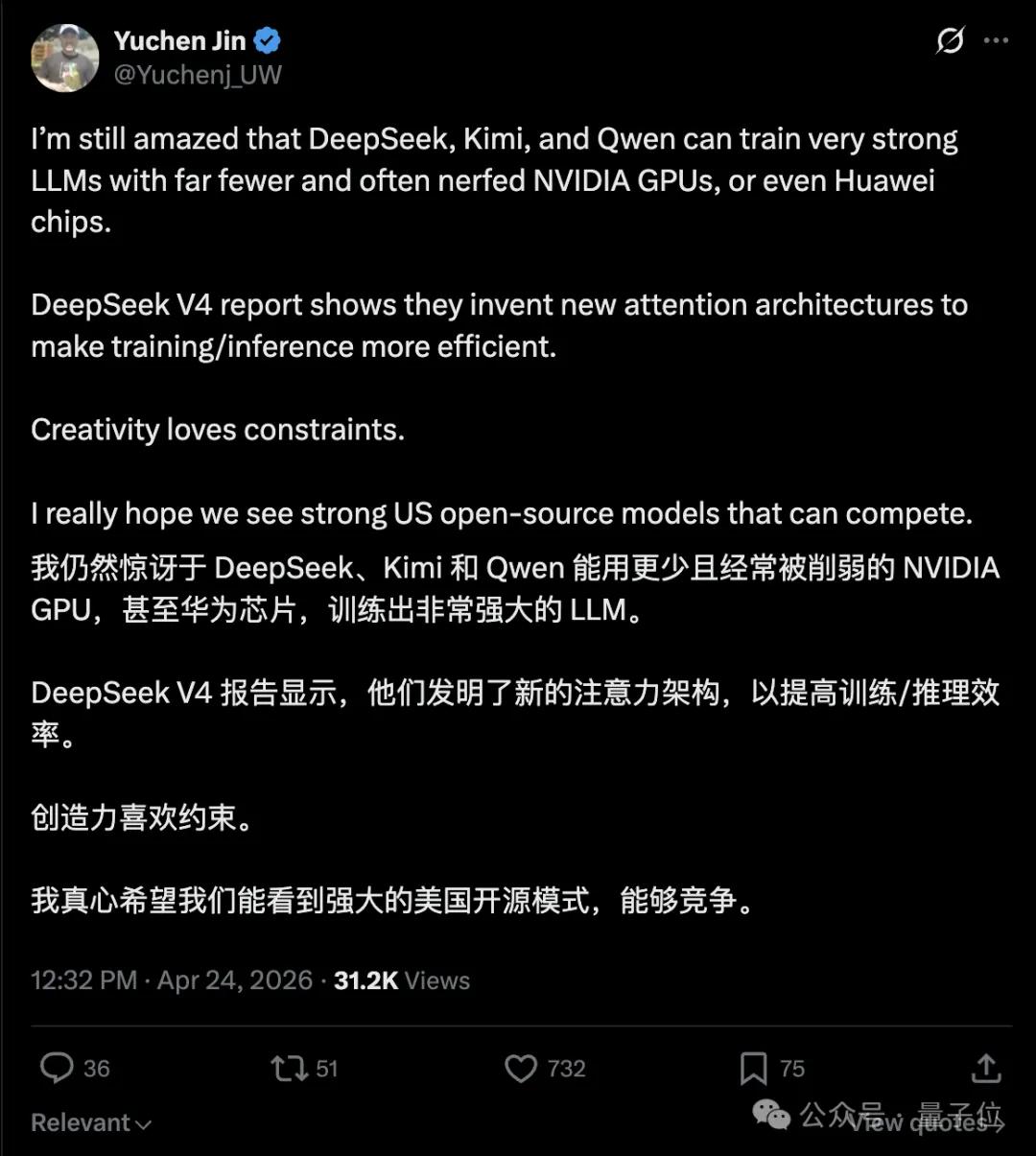
DeepSeek V4, although released six months late, has received overwhelming positive reviews and captured significant media attention, even overshadowing OpenAI.

The impressive creativity displayed by DeepSeek under limited conditions has garnered admiration, especially as it remains committed to an open-source approach in 2026.
While there is a wealth of information available, two main points stand out.
Key Features
-
Open Source Million-Token Context with Reduced KV Cache
V4-Pro and V4-Flash feature 1.6 trillion parameters / 284 billion parameters with a 1M context. In this scenario, V4-Pro’s single-token FLOPs are only 27% of V3.2, and the KV cache is reduced to 10%.
Amazon hardware engineer GPD noted that this could potentially solve the current HBM shortage.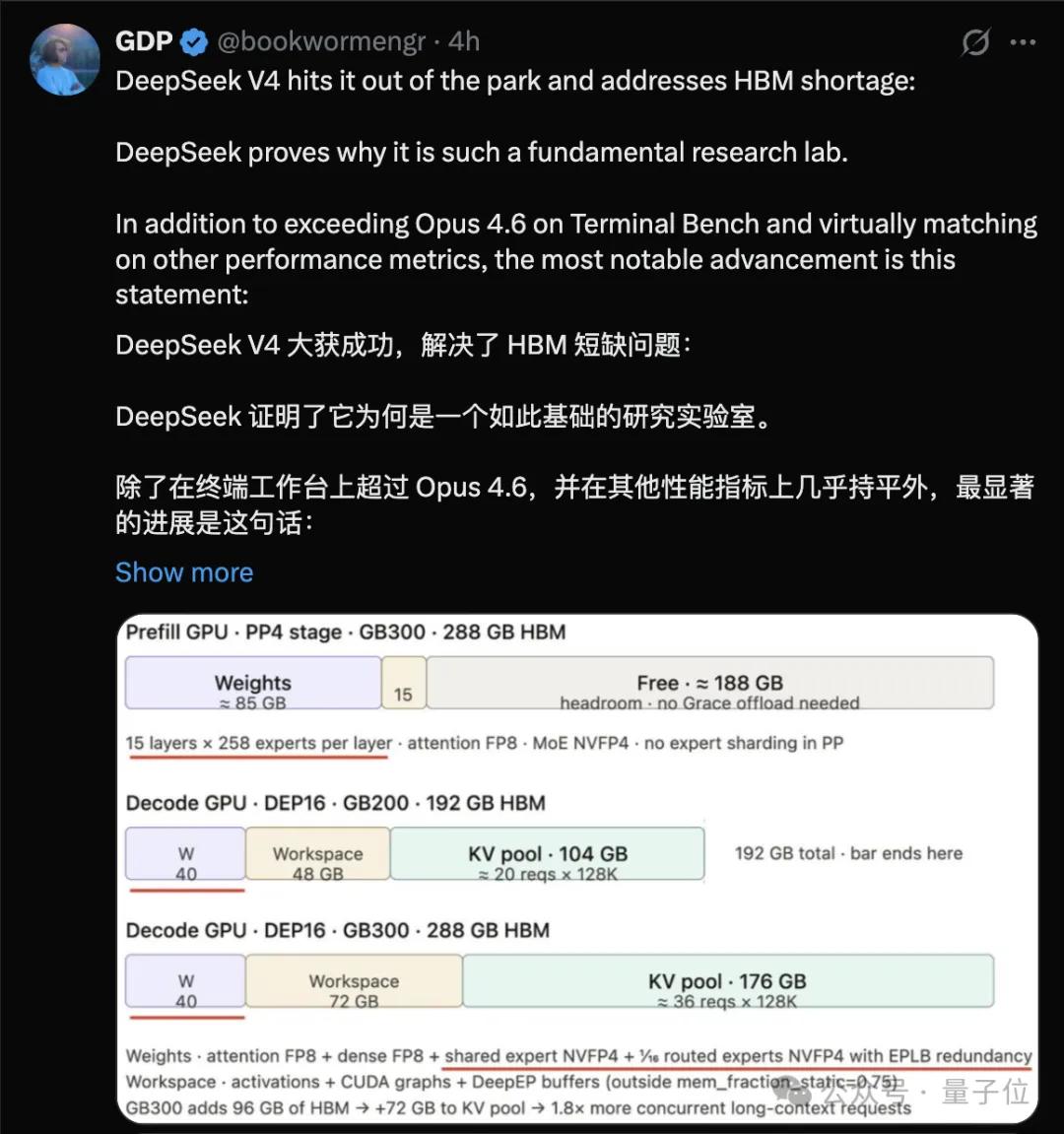
-
Domestic Chip Adaptation
The model now supports Huawei’s computing power, with the Ascend 950 super nodes expected to be mass-produced in the second half of the year.
Additionally, in the past four months, DeepSeek has released several papers that may contribute to V4, with today’s technical report now open-sourced for verification.
- mHC (Manifold-Constrained Hyper-Connections): Uploaded to arXiv on December 31, 2025, credited to Liang Wenfeng. Included in V4.
- Engram (Conditional Memory Module): Jointly released by DeepSeek and Peking University in January. Not included in V4 but mentioned for future directions, reserved for V5.
- DualPipe: Continues to be used, with adjustments made for mHC.
- Muon Optimizer: Borrowed from Kimi. V4 replaces AdamW, taking over most parameter training.
Four expectations, three realized, one reserved for the next generation.

Overall Architecture
The V4 generation represents the most extensive modifications in the DeepSeek series. Compared to V3, V4 has been upgraded in three areas:
- Introduction of mHC to strengthen residual connections.
- Design of a hybrid attention architecture, alternating between CSA (Compressed Sparse Attention) and HCA (Heavily Compressed Attention) to address long document efficiency.
- Adoption of Muon as the main optimizer.
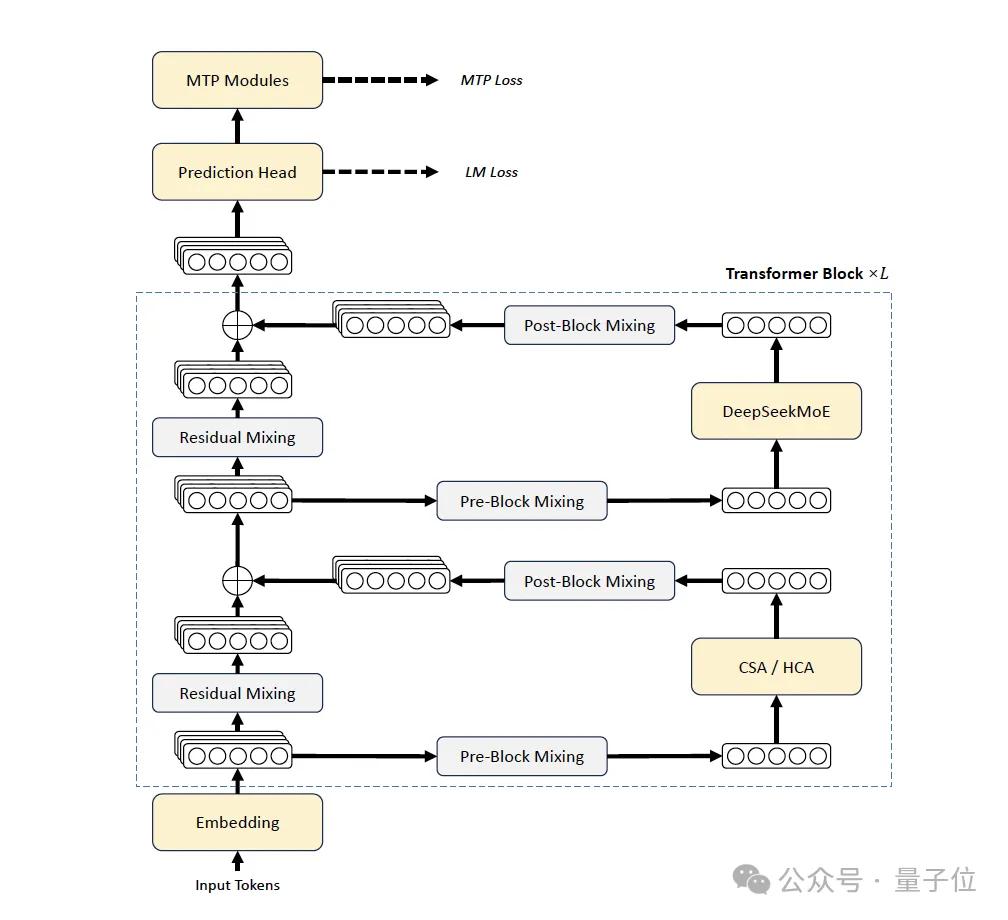
The MoE part continues to use DeepSeekMoE, and the MTP (Multi-Token Prediction) module remains consistent with V3.
Some detailed adjustments include changing the activation function of the affinity score from Sigmoid to Sqrt(Softplus(·)), removing constraints on the number of routing target nodes, and replacing the first few layers of dense FFN with MoE layers using Hash routing.
mHC: Adding Constraints to Residual Connections
Residual connections, introduced by He Kaiming in ResNet in 2016, have remained largely unchanged for a decade. However, as models grow deeper and parameters increase, traditional residual connections begin to show instability, making training more prone to failure.
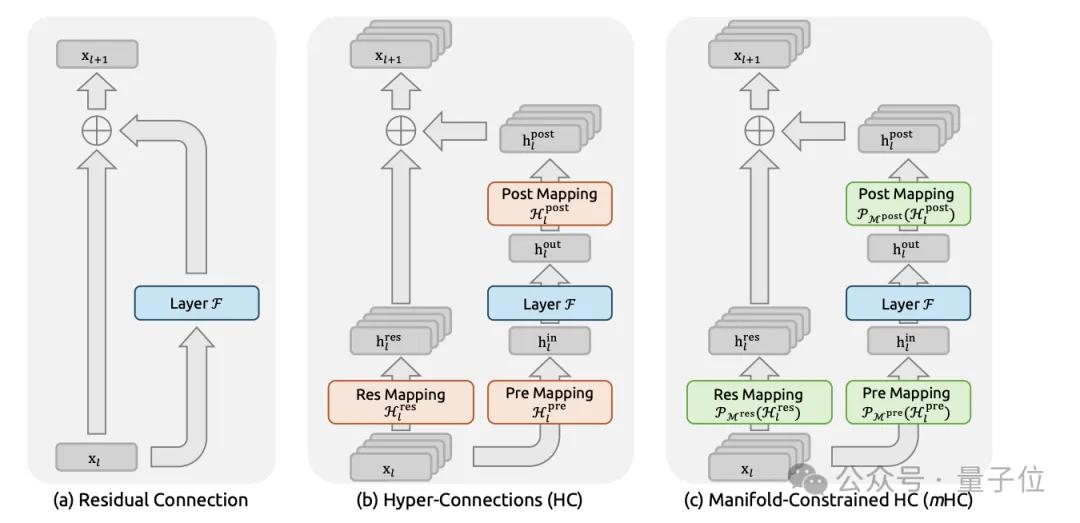
Hyper-Connections (HC) was a concept previously proposed by Kimi’s team, which transforms the residual flow from one-dimensional to n_hc parallel channels, mixing between layers using a matrix B.
DeepSeek found that HC often exhibited numerical instability during multi-layer stacking, leading to training failures.
The approach in V4, termed mHC, constrains matrix B to the manifold of “double stochastic matrices” (mathematically known as Birkhoff polytope), normalizing both rows and columns to 1. This constraint offers two benefits:
- The spectral norm of the matrix naturally does not exceed 1, providing a hard limit on residual propagation.
- Such matrices are closed under multiplication, ensuring stability even when many layers are stacked.
Input mapping A and output mapping C are ensured to be non-negative and bounded through the Sigmoid function, preventing signal cancellation.
The implementation uses Sinkhorn-Knopp iterations, alternating between row and column normalization, converging after 20 iterations. This process is executed for each layer.
While it may seem costly, DeepSeek has implemented a fused kernel combined with selective recomputation, keeping the wall-time overhead of mHC within 6.7% of the overlapped pipeline.
Technically, mHC is not a groundbreaking architectural innovation but rather an engineering patch that stabilizes large models. As model depth and parameter counts continue to rise, such patches will become essential.
Hybrid Attention Mechanism
This section is the most substantial in the paper and is the core magic behind the “million-token efficiency”.
The attention layer in V4 employs two alternating structures: CSA (Compressed Sparse Attention) and HCA (Heavily Compressed Attention).
CSA performs two tasks: compression and sparse selection.
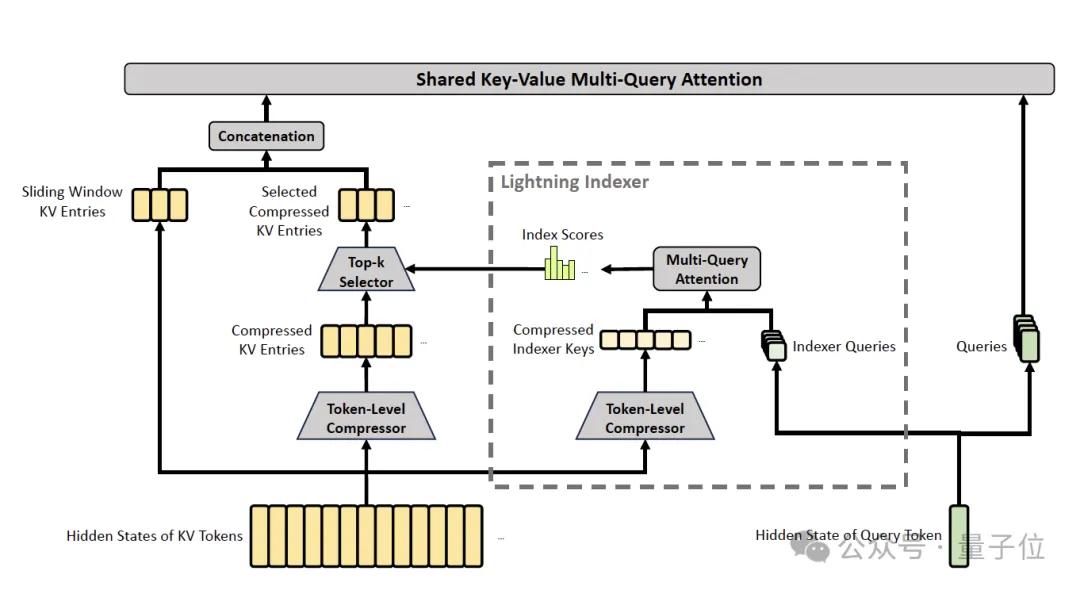
- KV Compression: Every m token’s KV entries are compressed into one using a learning-weighted attention-like mechanism.
- Lightning Indexer + Top-k Selection: This part is inherited from V3.2’s DSA. For each query token, a lightweight indexer computes its relevance score with each compressed KV block.
- Core Attention: Multi-Query Attention is performed on the selected top-k compressed KV blocks to obtain the attention output.
- Grouped Output Projection: Since V4 sets the head dimension c to 512 (much larger than V3.2’s 128), direct projection of all head outputs back to d dimensions would be costly. Thus, grouped projections are employed, dividing n_h heads into g groups, projecting each group to an intermediate dimension d_g before merging back to d.
Overall, CSA achieves two layers of compression: the first reduces sequence length from n to n/m, and the second performs sparse selection from n/m to top-k. For a 1M token sequence, instead of attending to 1M tokens, only 1024 compressed blocks are attended.
HCA employs a simpler and more aggressive approach, compressing more heavily without sparse selection.
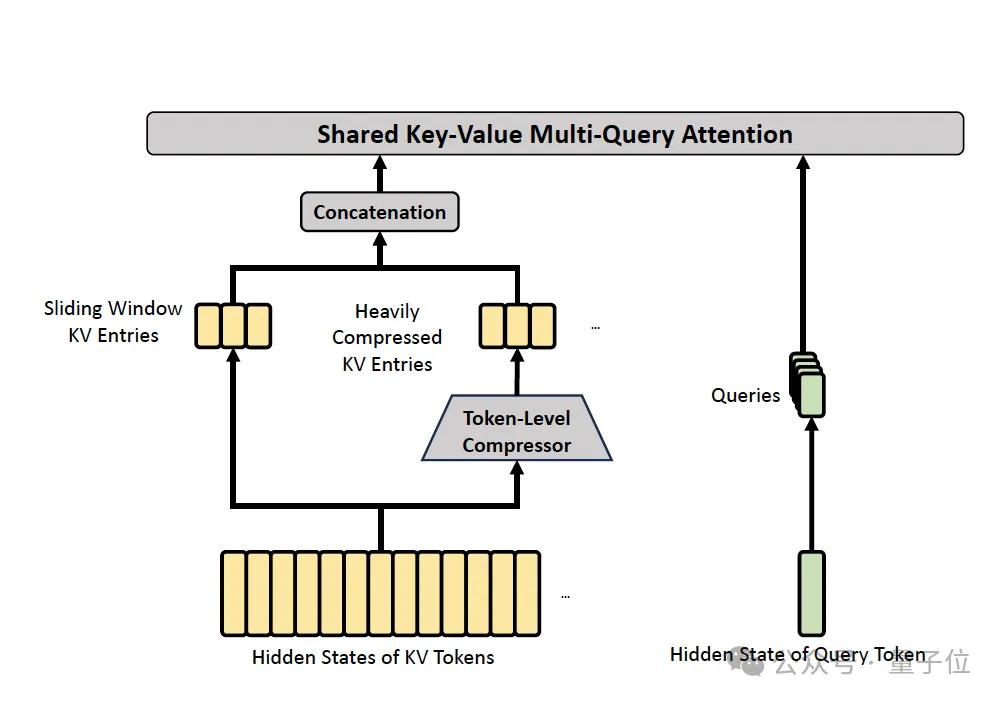
The compression rate m’=128 compresses every 128 tokens into one, without the overlap seen in CSA, directly compressing every m’ tokens as a group. Dense attention is then performed on all compressed KV.
While the paper does not elaborate extensively on why CSA and HCA are paired, the architecture chapter indicates their distinct roles. CSA’s gentle compression, relying on sparsity, is suitable for token-level fine retrieval, while HCA’s aggressive compression maintains density, ideal for global signal aggregation.
V4 alternates between the two. Pro features 61 layers, while Flash has 43 layers, stacking CSA and HCA in succession, ensuring no detail is overlooked while avoiding being bogged down by specifics.
Additionally, several tricks are revealed in the paper:
- Q/KV Normalization: Both CSA and HCA perform RMSNorm on query and KV entries before core attention to prevent attention logits from exploding.
- Partial RoPE: Rotational position encoding is applied only to the last 64 dimensions of query and KV entries, leaving the rest unchanged. Since KV entries serve as both key and value, naive RoPE would introduce absolute positional information to the output, thus a position of -i is applied on the output side to negate this, preserving only relative positional information.
- Sliding Window Attention as an Auxiliary Branch: To compensate for the strict causality ensured by compressed attention, V4 adds a sliding window branch, allowing each query to access the uncompressed KV of the last 128 tokens in addition to the compressed KV.
- Attention Sink: Borrowing from OpenAI and StreamingLLM’s trick, a learnable sink logit is added to the denominator of attention, allowing the sum of attention scores to differ from 1. This is particularly useful in long sequences, preventing the model from being forced to evenly distribute attention.
Muon Optimizer
In V4 training, most parameters are optimized not by AdamW but by Muon.
Muon, validated on smaller models by Keller Jordan’s team (now at OpenAI), is based on matrix orthogonalization. It optimizes only 2D parameter matrices, while other parameters (embedding, prediction head, RMSNorm weights, static biases of mHC, etc.) continue to use AdamW.
The first large-scale validation of Muon on LLM scale was Kimi K2. In 2025, Moonshot trained a 1T parameter MoE with 15.5T tokens using Muon (along with their QK-Clip variant, collectively referred to as MuonClip) without any crashes.
DeepSeek has also adopted Muon but has developed its version, hybrid Newton-Schulz iterations, executed in two segments over 10 steps:
- The first 8 steps use an aggressive coefficient to quickly push singular values towards 1.
- The last 2 steps use a gentle coefficient to precisely stabilize singular values at 1.
A noteworthy detail is that Kimi requires QK-Clip with Muon to prevent attention logits from exploding, while DeepSeek does not. Their rationale is that V4’s attention architecture allows direct RMSNorm on query and KV, addressing the explosion potential at the source.
Two companies, using the same optimizer to tackle the same issue, have taken different paths. This cross-team technical sharing and individual evolution represent one of the most interesting aspects of the open-source community in 2026.
Model Training
The DeepSeek-V4 series has doubled its pre-training data volume.
In contrast to V3’s 14.8T tokens, V4-Flash and V4-Pro consume 32T and 33T tokens, respectively—an increase of over 1.2 times.
The data composition prioritizes long document data, focusing on curating scientific papers and technical reports with academic value. The tokenizer still employs V3’s 128K vocabulary.
In terms of architecture, V4-Flash has 43 layers with a hidden dimension of 4096. MoE uses 1 shared expert + 256 routed experts, activating 6 per token, totaling 284B parameters with 13B activated.
V4-Pro has 61 layers with a hidden dimension of 7168. MoE uses 1 shared expert + 384 routed experts, also activating 6 per token, totaling 1.6T parameters with 49B activated.
Training scheduling involves four stages of sequence lengths: 4K → 16K → 64K → 1M. Sparse attention is not enabled from the start; dense attention is used for the first 1T tokens, introducing sparsity only when expanding to 64K.
The paper notes a serious loss spike during training, and DeepSeek discovered two makeshift solutions: Anticipatory Routing and SwiGLU Clamping. The paper candidly states that while these tricks work, the underlying mechanisms remain an open question.
In 2026, it is rare for a team that has trained two trillion-parameter MoEs to admit, “We do not know why these two tricks work.”
In the post-training phase, V4 underwent a methodological replacement, with the traditional mixed RL stage completely replaced by On-Policy Distillation (OPD).
The process unfolds in two steps:
- Training Domain Specialists: Independent experts are trained in mathematics, coding, agents, and instruction following. Each undergoes SFT for foundational training, followed by domain-specific RL using GRPO. V4 introduces three levels of reasoning effort modes: Non-think, Think High, and Think Max, each producing different output lengths.
- OPD Merging: Several experts are distilled into a unified student through on-policy distillation. The student performs rollouts, minimizing reverse KL to align with corresponding domain experts. Mathematical tasks align with the math expert, while programming tasks align with the coding expert.
While the methodology appears elegant, engineering constraints necessitate that each teacher is trillion-scale, with a vocabulary size exceeding 100,000. V4’s approach involves offloading teacher weights to distributed storage for on-demand loading, caching only hidden states without materializing logits, ensuring each mini-batch loads only one teacher head based on teacher sorting.
A seemingly elegant post-training methodology is underpinned by numerous engineering compromises that make it feasible.
Experimental Conclusions
In the experimental section, three key points stand out:
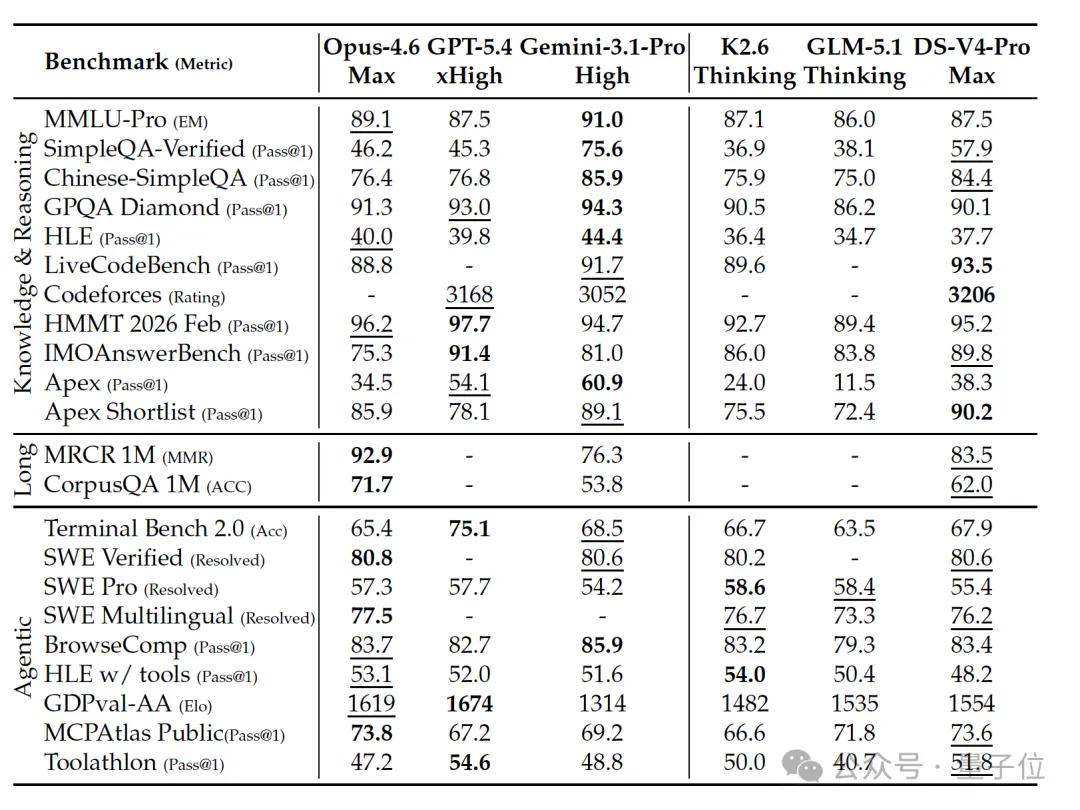
- Leading Open Source: V4-Pro-Max achieved 57.9 on SimpleQA-Verified, surpassing K2.6 at 36.9 and GLM-5.1 at 38.1, leading all open-source models by 20 percentage points.
- Competing with Closed Source: With a Codeforces rating of 3206, it exceeds GPT-5.4’s 3168 and Gemini-3.1-Pro’s 3052, ranking 23rd among human competitors. This marks a genuine competition between open-source and closed-source leaders.
- Existing Gaps: On HLE, V4-Pro-Max scored 37.7, while Gemini-3.1-Pro scored 44.4 and Claude-Opus-4.6-Max scored 40.0. In 1M MRCR, V4 outperformed Gemini but clearly lagged behind Claude, indicating a 3-6 month gap in knowledge and cutting-edge reasoning tasks.
The paper states:
DeepSeek-V4-Pro-Max outperforms GPT-5.2 and Gemini-3.0-Pro on standard reasoning benchmarks but slightly lags behind GPT-5.4 and Gemini-3.1-Pro, indicating a development trajectory approximately 3 to 6 months behind the leading closed-source models.
Flash-Max may be the most underrated aspect of this paper.
V4-Flash-Max activates only 13B parameters and can match GPT-5.2 and Gemini-3.0-Pro on reasoning tasks, even exceeding K2.6-Thinking in coding and mathematics.
In terms of active parameter efficiency, it ranks among the most efficient reasoning models available.
In practical tasks, the internal R&D code benchmark shows V4-Pro-Max at 67%, close to Claude Opus 4.5’s 70%. In a survey of 85 internal developers, 91% indicated that V4-Pro could serve as the primary coding model.
Official tweets also indirectly confirm this:
Currently, DeepSeek-V4 has become the Agentic Coding model used by company employees, with feedback indicating a better user experience than Sonnet 4.5, with delivery quality approaching Opus 4.6 in non-thinking mode, but still showing some gaps compared to Opus 4.6 in thinking mode.
In the paper’s conclusion, DeepSeek states:
To pursue ultimate long document efficiency, the V4 series adopts a relatively aggressive architectural design. To mitigate risks, we retained many validated components and tricks, resulting in a relatively complex architecture. In future iterations, we will conduct more comprehensive and principled research to streamline the architecture to its essential elements.
Future directions include exploring new dimensions of sparsity (notably mentioning the Engram line), low-latency architectures, long-term multi-turn agentic tasks, multimodality, and improved data curation.
An interesting detail is that in formal mathematical evaluations, DeepSeek humorously left some entries blank for K2.6 and GLM-5.1, citing their APIs being too busy to return results in a timely manner.

Conclusion
Placing V4 back into the complete trajectory of DeepSeek, it is not merely chasing the frontier.
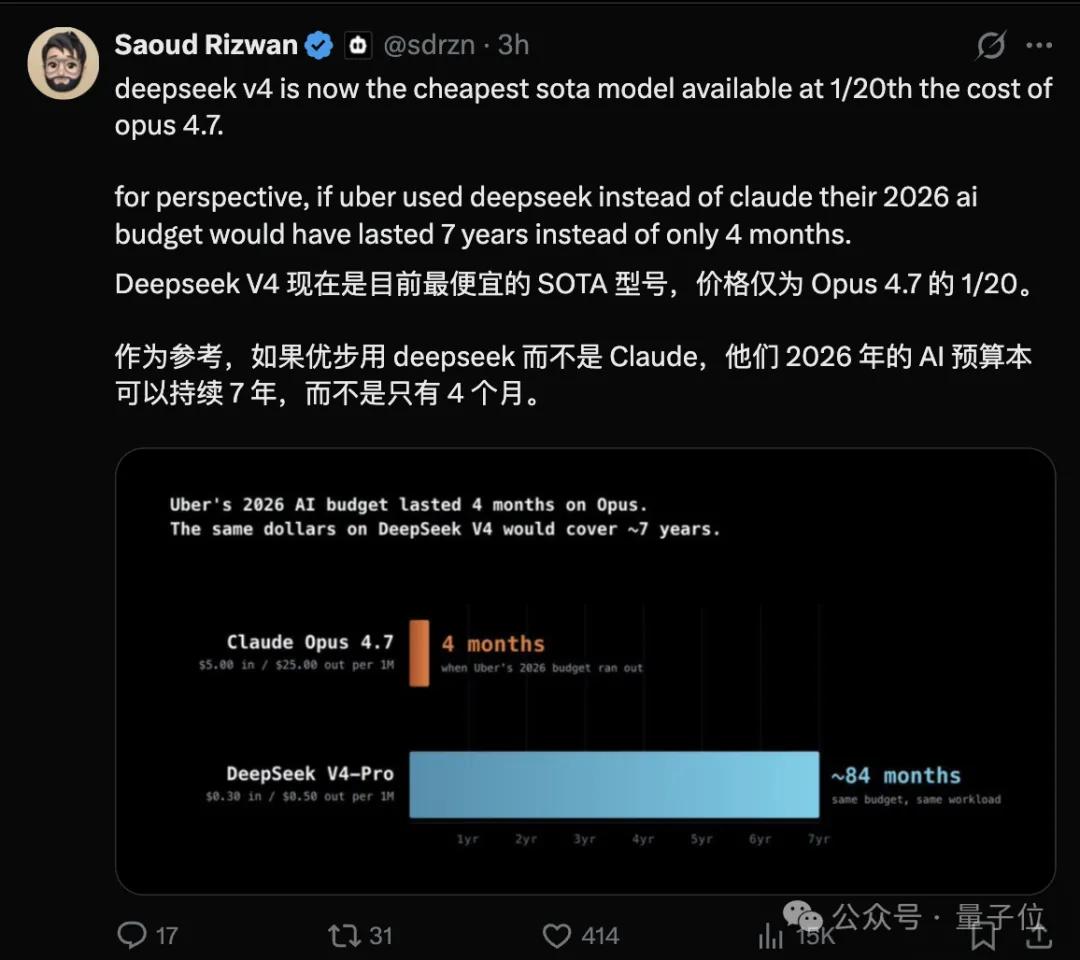
The trends over the past three years are clear. Closed-source companies pursue capability ceilings, aiming for higher scores on HLE. DeepSeek has consistently pursued a different line: minimizing costs while maintaining similar capabilities.
V4 has pushed this to the million-token level. A 1M context under V3.2’s cost structure is unsustainable, as the KV cache would consume all available memory. V4 reduces it to 10% of V3.2, resulting in a drastic flattening of the cost curve.
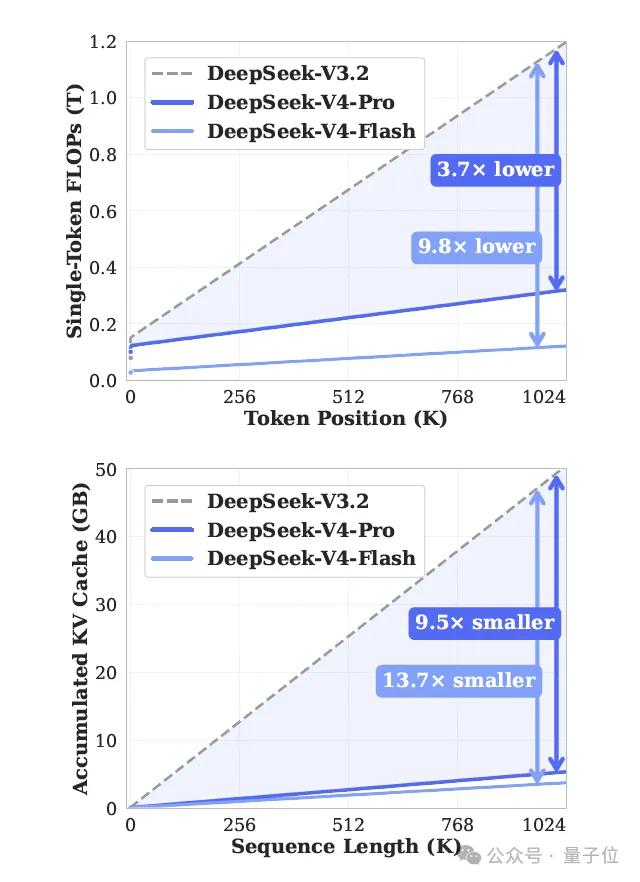
What will the results be? In scenarios such as a long agent conversation, a repeatedly referenced technical document, or a cross-repository refactor, what previously required windowing, retrieval, and careful context management can now be handled by V4 as “just throw it all in and see what happens.”
DeepSeek’s actions over the years have been clear: a consistent effort to simplify. Starting from V2’s MLA, each generation has aimed to reduce KV cache, activation parameters, and attention computation.
By the time of V4, single-token inference FLOPs have been cut to a quarter, and KV cache to a tenth.
The million-token context is not a new capability; it is a cost-effective means of handling the same context window.
One More Thing
The paper concludes with a lengthy list of contributors, including Liang Wenfeng.

Several names marked with asterisks are researchers who have left the team but made significant contributions to V4.
Over the past year, there have been multiple rounds of news regarding talent loss at DeepSeek. However, this list ties their names to the long-awaited V4 model, shared with the community after over a year of anticipation.
Every individual counts, and every day matters.
On the day of V4’s release, DeepSeek researcher Chen Deli reposted on X, stating:
DeepSeek-V3: December 26, 2024.
DeepSeek-V4: April 24, 2026.
484 days later, we humbly share this labor of love.
As always, we remain committed to long-termism and universal open source.
AGI belongs to everyone.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.